Overview
The CCPP project is designed to facilitate research on "Classical Chinese Poetry-to-Painting" generation. It provides a high-quality benchmark, human-created painting samples, MLLM-generated painting outputs, and tools for data processing/evaluation. The project aims to enable reproducible research on evaluating MLLMs’ understanding of classical Chinese culture (poetry, idioms, classical prose) and their cross-modal generation capabilities. We provide a partial dataset (300 samples) and human-painting. The full dataset will be released upon paper acceptance.CCPP-Bench
Statistics
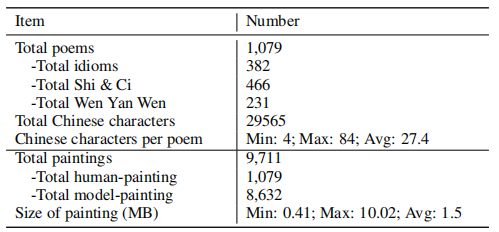
The statistics of dataset
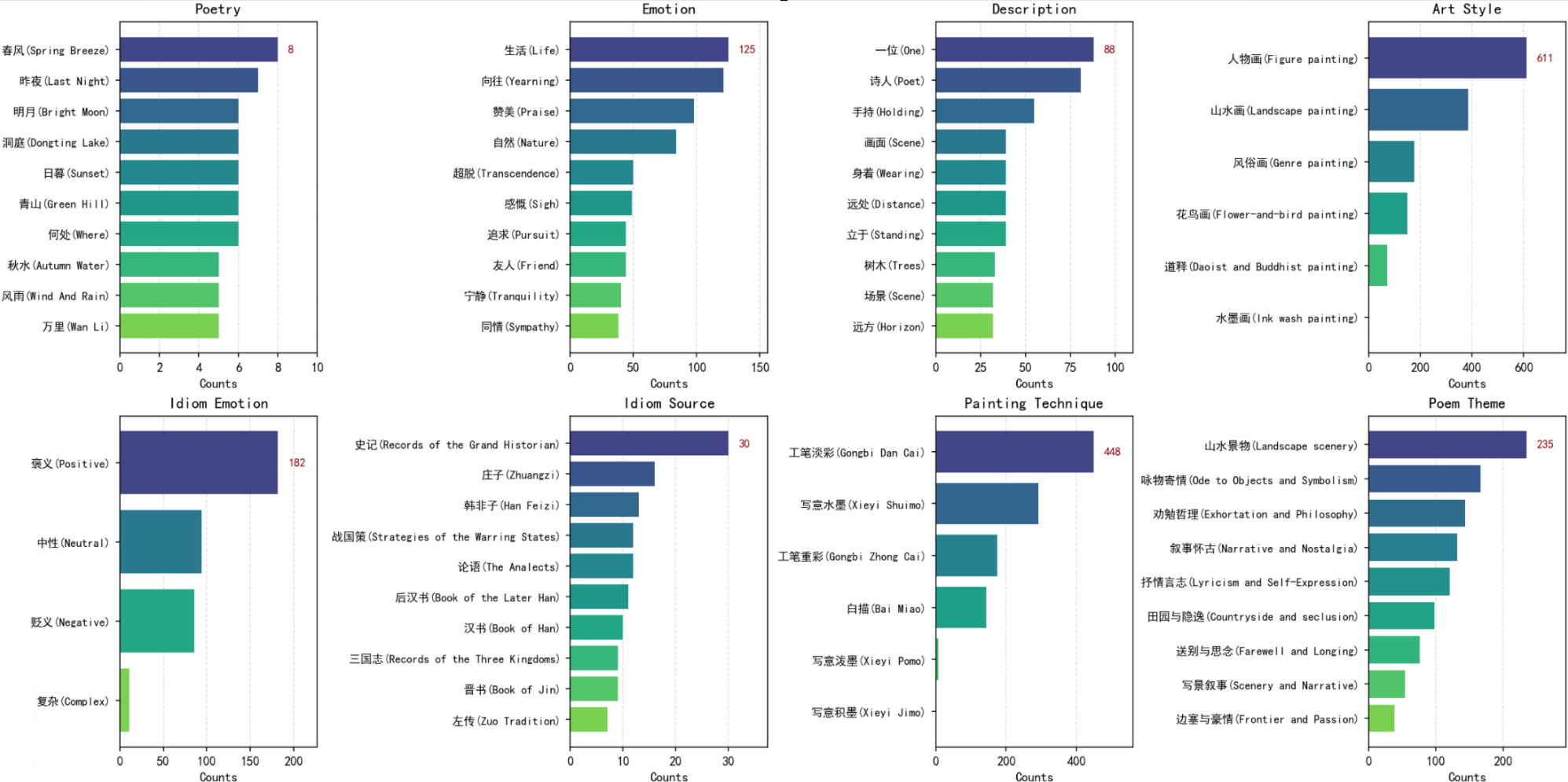
The distribution of keywords
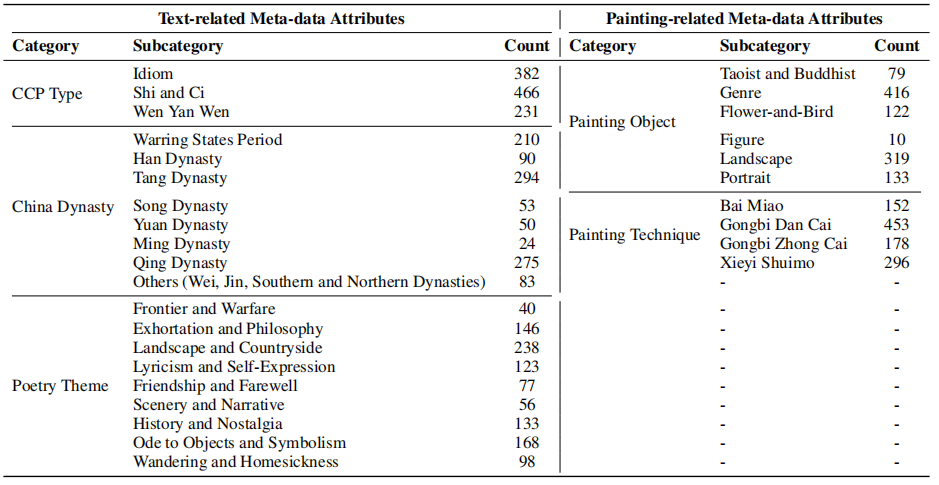
Fine-grained statistics of CCPP-Bench (one-level), i.e., the total number of samples in terms of different meta-data. In particular, we list meta-data attributes classified into poetry-related and painting-related.
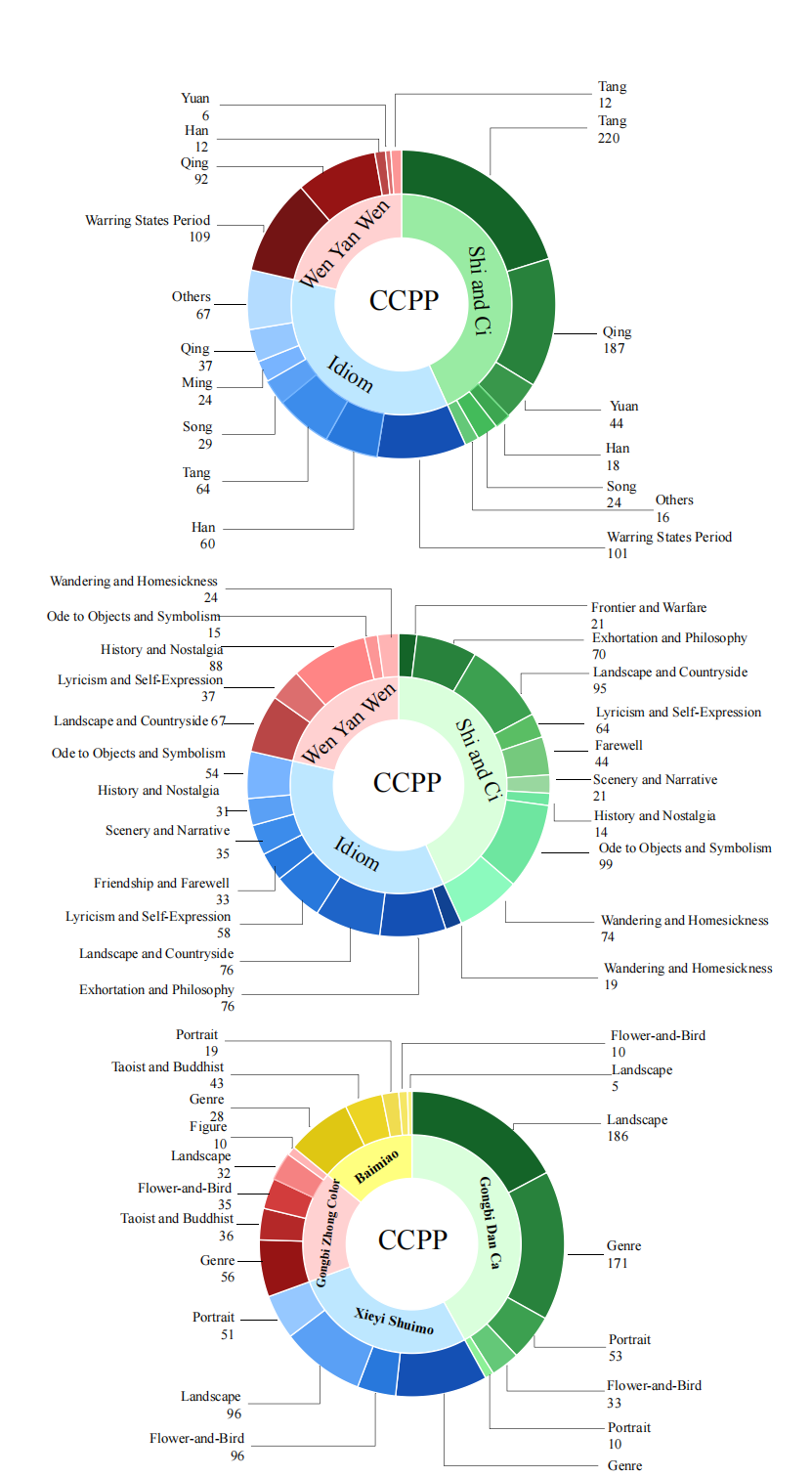
Fine-grained statistics of CCPP-Bench (two-level). Top: type (primary) and dynasty (secondary); Middle: type (primary) and theme (secondary); Bottom: painting techniques (primary) and painting objects (secondary).
Results and Analysis
Results.Results show a significant gap between MLLMs and human performance. Adding explanations improves cultural and historical accuracy, but all models struggle with deep implication and cultural precision. Automatic metrics correlate poorly with human judgments, and even stronger models fail on challenging dimensions.
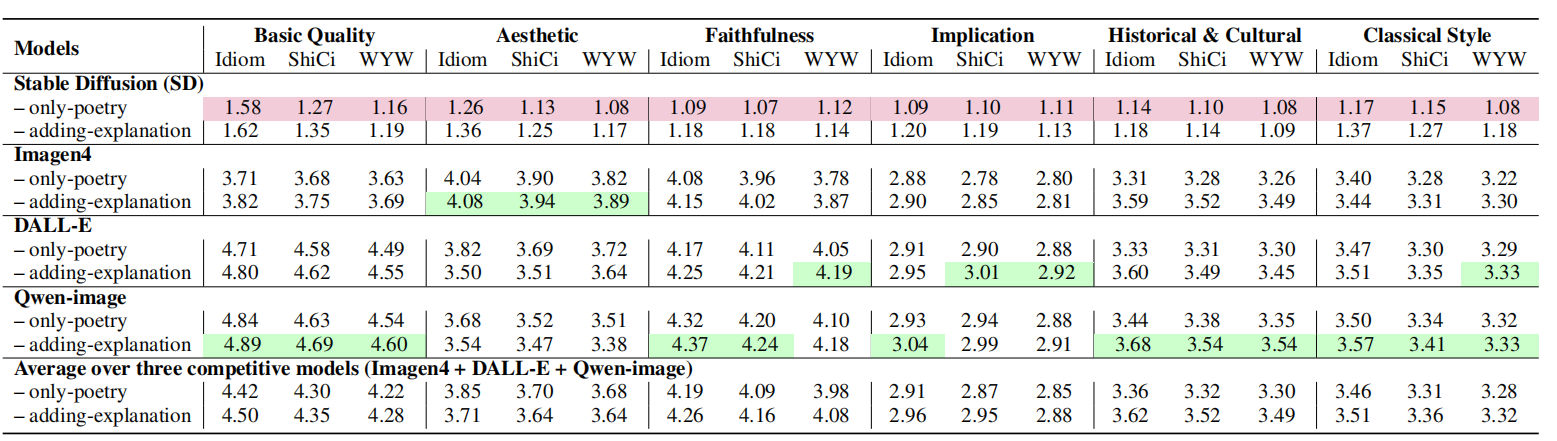
Performance comparison of 4 MLLMs. We report the human annotated scores (on a scale of 1 to 5) averaged on specific instances for each model in two input modes. The column-wise highest scores and lowest scores are highlighted.
Error Analysis.Ten major error types are identified, including Chaotic generation,Thematic irrelevance,Incorrect inscription,Inappropriate era-style,Common-sense error,Common-sense error,Poetry misunderstanding,Aesthetic error,Excessive AI-style and Emotional inconsistency.
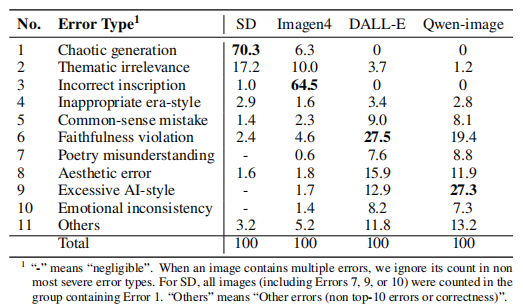
Error ratios (%) of 4 MLLMs on the whole dataset.
Error Examples





Conclusion & Contributions
This work pioneers the systematic evaluation of classical Chinese poetry-to-painting generation. CCPP-Bench lays a solid foundation for future research in multimodal evaluation, cultural generation, and humanities-oriented AI.